12 Big data
12.1 Drahtlose Kommunikationssysteme
Synonyme
Floating Car Data (FCD), Dedicated Short-Range Communications (DSRC/ITS-G5 in Europa), Vehicle-to-X (Auto und Infrastruktur) (C2x/V2x), Cellular-V2X-Technologie (C-V2X), Vehicular ad hoc network (VANET)
Definition
Von 1G bis 5G, die Bedeutung der Mobilfunkstandards (Jahr der Einführung, Bandbreiten-Download) (Techbook, 2020):
- 1G: Der Mobilfunk der ersten Generation arbeitete noch mit analoger Sprachübertragung.
- 2G (bis zu 14,4 kbit/s): Digitale Sprachübertragung im D-Netz (1992) mit dem GSM-Standard.
- 2.5G, GPRS (2001, bis zu 55 kbit/s): Digitale Datenübertragung.
- 2.75G, EDGE (2006, bis zu 150 kbit/s.): Weiterentwicklung von GSM durch Verwendung eines effizienteren Modulationsverfahrens. Das erste iPhone nutzte EDGE.
- 3G, UMTS (2004, bis zu 384 kbit/s): Dieser Mobilfunkstandard ermöglicht das gleichzeitige Senden und Empfangen mehrerer Datenströme durch eine neue Funkzugangstechnologie.
- 3.5G, HSPA (2006, bis zu 42 Mbit/s): Erweiterung von UMTS.
- LTE (2010, bis zu 50 Mbit/s): Standard, der auf der UMTS-Infrastruktur aufbaut.
- 4G, LTE Advanced (2014, bis zu 300 bis 400 Mbit/s): Die Latenzzeiten wurden verkürzt und die Funkkapazitäten erhöht.
- 5G (2020, bis zu 100 Gbit/s, aber die schnellste bisher gemessene Geschwindigkeit beträgt 1,8 Gbit/s): Der neueste Mobilfunkstandard mit sehr geringen Latenzzeiten für Echtzeitreaktionen. 5G lässt sich jedoch nicht so einfach an bestehenden Mobilfunktürmen nachrüsten, da die Wellen sehr komprimiert und zwischen 1 und 10 Millimeter lang sind (bisherige Mobilfunkwellen sind mehrere Zentimeter lang). Zur Entlastung des heutigen Netzes werden Frequenzen zwischen 6 und 300 Gigahertz (GHz) verwendet. Zum Vergleich: Das heutige Mobilfunknetz arbeitet im Spektrum zwischen 0,8 und 2,6 GHz. Die höheren Frequenzen und kürzeren Wellen haben jedoch den Nachteil, dass Wände und Hindernisse nicht mehr so leicht durchdrungen werden können. Die Funkzellen müssen daher engmaschiger angeordnet werden. Für schnelle Reaktionszeiten von weniger als einer Millisekunde werden mehr Antennen pro Zelle als Abonnent:innen benötigt. In einigen Ländern, darunter Deutschland, hat die Versorgung mit 5G bereits begonnen. Kritiker:innen befürchten jedoch eine höhere Strahlenbelastung durch 5G und damit gesundheitliche Auswirkungen, die noch nicht kalkulierbar sind.
In den letzten Jahren haben sich zwei wichtige Standards für die Fahrzeugkommunikation im zugewiesenen Frequenzband von 5,9 GHz entwickelt (Abbildung 12.1). Dabei handelt es sich zum einen um das in den USA entwickelte Dedicated Short-Range Communications (DSRC)-Protokoll und zum anderen um das vom Europäischen Institut für Telekommunikationsnormen (ETSI) entwickelte Intelligent Transportation System (ITS) G5-Protokoll. Diese Standards basieren auf der IEEE 802.11p-Zugangsschicht, die für Fahrzeugnetzwerke entwickelt wurde (Mannoni et al., 2019). DSCR (IEEE 802.11p) wird in Europa als ITS-G5 bezeichnet, das seit 20 Jahren gut erforscht ist und eine ausreichende technische Reife für den aktuellen Einsatz erreicht hat. Trotz der Empfehlung aus dem Jahr 2011, das IEEE 802.11p-Protokoll als Standard für die Fahrzeugkommunikation zu verwenden (IEEE, 2014), haben in den letzten Jahren viele Forscher:innen und Industrieunternehmen die Verwendung des LTE-Mobilfunknetzes als alternative Lösung für Fahrzeugvernetzungsanwendungen in Betracht gezogen, insbesondere für den Transport von Floating Car Data FCD-Nachrichtenströmen (Salvo et al., 2017). Auch wenn Cellular Vehicle to Everything (C-V2X) eine recht neue Technologie ist, basiert sie auf der Familie der 3GPP-Standards (3rd Generation Partnership Project), die in fast allen Teilen der Welt erfolgreich eingesetzt werden (Sattiraju et al., 2020) (erste Versuche Ende 2017 (Fillenberg, 2017)).
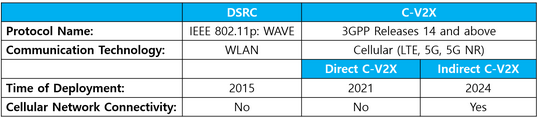
Figure 12.1: DSRC und C-V2X (Autocrypt, 2021)
Der Begriff “Cellular” in C-V2X kann für Verwirrung sorgen. “Zellular” bezieht sich in diesem Zusammenhang nicht auf die Nutzung von Mobilfunknetzen, sondern auf die Nutzung der zugrunde liegenden Elektronik in Mobilfunkgeräten, die für die direkte Kommunikation von einem Funkgerät zum anderen angepasst sind. Nach (Gettman, 2020) sind die wichtigsten Gemeinsamkeiten und Unterschiede zwischen DSRC- und C-V2X-Technologie die folgenden:
Ähnlichkeiten
- Sowohl DSRC als auch C-V2X nutzen das 5,9-Ghz-Band für die direkte Kommunikation von einem Funkgerät zum anderen.
- Beide Technologien verwenden die gleichen Nachrichtensätze (SAE J2735 und J2945) und Anwendungsfälle.
- Beide Technologien verwenden digitale Signaturen, um die Sicherheit und das Vertrauen in die Nachrichtenanbieter zu gewährleisten.
- In beiden Fällen gibt es keine Verbindung zwischen den Funkgeräten. Jedes Funkgerät überträgt den Standort, die Geschwindigkeit, die Beschleunigung und andere Statuselemente des Fahrzeugs, während es andere Funkgeräte abhört.
Unterschiede
- DSRC verwendet einen Funkstandard namens WAVE, während C-V2X Long-Term Evolution (LTE) verwendet - die Chip-Technologie, die fast alle Mobiltelefone nutzen. Ein DSRC-Funkgerät kann nicht mit einem C-V2X-Funkgerät sprechen und umgekehrt.
- Die Reichweite von DSRC beträgt in der Regel 300 m, und viele Installationen haben gezeigt, dass eine viel höhere Reichweite möglich ist. Erste Tests von C-V2X zeigen, dass die Reichweite 20-30 % größer ist als bei DSRC und dass die Leistung bei Hindernissen deutlich verbessert werden kann. Obwohl C-V2X anfänglich eine bessere Leistung zu haben scheint, ist die Reichweite und Zuverlässigkeit von DSRC für die wichtigsten Sicherheitsanwendungen mehr als ausreichend.
Ebenfalls relevant für die drahtlose Kommunikation im Verkehrssektor ist das VANET, ein Ad-hoc-Netz für Fahrzeuge. Es ist eine Unterklasse der mobilen Ad-hoc-Netze (MANETs), wobei es von fahrenden Fahrzeugen gebildet wird. VANET wird zunehmend bei der Bewältigung von Staus im Berufsverkehr eingesetzt. Die größte Herausforderung in VANET ist die Zusammenarbeit zwischen den Knoten. Denn selbst die beste Lenkungskonvention wäre nicht von Vorteil, wenn die Knotenpunkte nicht an der Übermittlung der Informationen teilnehmen (Rath et al., 2019).
Wichtige Interessensgruppen
- Betroffene: Fahrer:innen von Personenkraftwagen, Fahrer:innen von Nutzfahrzeugen, Versicherungen
- Verantwortliche: Nationale Regierungen, Technologieunternehmen, Automobilhersteller, Infrastrukturhersteller
Aktueller Stand der Wissenschaft und Forschung
Lange vor der Entwicklung von 5G wurde die V2X-Kommunikation untersucht. Viele Analyst:innen und Branchenvertreter:innen gehen davon aus, dass 5G aufgrund der neuen Geschwindigkeiten und anderer technischer Fortschritte in 5G die zukünftige Technologie für die V2X-Kommunikation sein wird. Folglich muss die Sicherheit von 5G und die Frage, wie sie in das aktuelle IVS-Modell integriert werden kann, eingehend untersucht werden (Annu et al., 2021).
Einige Forschungsarbeiten befassen sich mit verschiedenen Materialien und ihren Eigenschaften für die drahtlose Kommunikation (Nitika et al., 2021). Es wird auch bereits an den Spezifikationen für 6G-Antennen für die nächste Generation geforscht. Das Terahertz (THz)-Frequenzband (0,1-10 THz) wird im drahtlosen 6G-Kommunikationssystem verwendet werden, um die Nachfrage der Nutzer:innen nach höheren Datenraten und Ultra-Hochgeschwindigkeits-Kommunikation für viele zukünftige Anwendungen zu unterstützen (Hajiyat et al., 2021). Darüber hinaus testen Zhao et al. (2019) ein DSRC-basiertes Kollisionswarnsystem, da die Genauigkeit von GPS leicht von der Fahrumgebung betroffen ist, insbesondere wenn es abgeschirmt ist. Die Multi-Sensor-Fusions-Positionierungstechnologie ist eine vielversprechende Methode, um die Genauigkeit der Sicherheitsabstandsberechnung zu verbessern und eine spurgenaue Positionierung zu erreichen.
Mannoni et al. (2019) verglichen TS-G5 und C-V2X für die V2X-Kommunikationssysteme. Es zeigte sich, dass C-V2X bei gleicher Datenrate eine bessere Flexibilität und Leistung als ITS-G5 aufweist. Basierend auf der Leistung der physikalischen Schicht wurde das Verhalten der beiden Standards in einem Netzwerk ohne Mobilfunkabdeckung und mit mehreren Fahrzeugen bewertet. Die Simulationen zeigten, dass C-V2X bei geringer Nutzerdichte besser abschneidet als ITS-G5. Allerdings verschlechtert sich die Leistung von C-V2X stärker als die von ITS-G5, wenn der Grad der Überlastung zunimmt. Der Vergleich der Ressourcenzugriffszeit (Latenzzeit) zeigt einen Vorteil für ITS-G5, aber die Gesamtlatenz ist nicht eindeutig besser, da sie stark von der Nutzerdichte und der Abdeckung abhängt..
Die Ergebnisse von Sattiraju et al. (2020) zeigen auch, dass C-V2X die IEEE 802.11p DSRC (ITS-G5) Technologie für fast alle betrachteten Kanalmodelle übertrifft, mit einem Gewinn von 0-5 dB. Außerdem zeigen die Ergebnisse, dass C-V2X bei höheren Fahrzeuggeschwindigkeiten besser abschneidet. Diese bessere Leistung von C-V2X kann auf die Verwendung des Turbo-Encoders und den besseren Kanalschätzungsmechanismus zurückgeführt werden, der eine höhere Anzahl von DMRS-Symbolen verwendet.
Salvo et al. (2017) haben in ihrer Forschung über heterogene zellulare und DSRC-Netzwerke für die Datenerfassung von Floating Car in städtischen Gebieten gezeigt, dass es sinnvoll ist, sich auf direkte V2V-Kommunikationsverbindungen (ITS-5G) zu verlassen, bevor Daten über LTE-Kanäle (C-V2X) gesendet werden. Die vorgeschlagene Lösung passt sich vollständig an die verfügbare Durchdringungsrate der VANET-Ausrüstung an; sie fällt automatisch auf eine reine LTE-FCD-Erfassung zurück, wenn die VANET-Ausrüstung nicht verfügbar oder zu spärlich ist. Der erreichbare Durchsatz bei der FCD-Erfassung ist ein Schlüsselthema angesichts der enormen Menge an Sensordaten, die potenziell von fahrenden Fahrzeugen erfasst werden können, z. B. können bis zu 100 Mbit/s über den CAN-Bus eines Fahrzeugs übertragen werden (Kang et al., 2016). Diese extremen Echtzeit- und hochauflösenden Big Data erfordern neue Ideen für die verteilte Verarbeitung und Vernetzung, um den Weg für intelligente Anwendungen zu ebnen - ein Trend, der bisher wenig erforscht wurde (Salvo et al., 2017).
Aktueller Stand der praktischen Umsetzung
In Europa ist DSRC die derzeit am häufigsten verwendete Technologie. So brachte VW 2019 seinen Golf 8 mit DSRC-basiertem V2X auf den Markt. Damit wurde Europas beliebtestes Auto zum ersten Massenmarktfahrzeug mit V2X. In anderen Teilen der Welt ging DSRC-basiertes V2X nach einigen groß angelegten Feldversuchen 2015 in Japan und 2017 in den USA in ausgewählten Fahrzeugmodellen in Serie. Während DSRC-basiertes V2X in Europa und Japan eingesetzt wird, gewinnt C-V2X in anderen Regionen an Dynamik. China zum Beispiel treibt die Einführung von C-V2X voran. Anfang 2020 wurde der Chipsatz von Autotalk für ein C-V2X-Massenproduktionsprogramm in China ausgewählt (Autotalks Ltd., n.d.).
DSRC und C-V2X arbeiten mit unterschiedlichen Kommunikationstechnologien, und die Zugangsebene ist nicht interoperabel. Dies stellt Automobilhersteller und Infrastrukturentwickler vor die schwierige Entscheidung, ob sie die eine oder die andere Technologie bevorzugen sollen. Viele Chip-Hersteller arbeiten jedoch an der Produktion von Dual-Mode-Chipsätzen, die mit beiden Standards kompatibel sind, was den Automobilherstellern den Wechsel erleichtert. Was die Infrastrukturentwickler betrifft, so arbeiten viele von ihnen mit bestehenden DSRC-Infrastrukturen, um durch die Kombination mit indirektem C-V2X die Konnektivität mit Mobilfunknetzen zu erhöhen. Unabhängig von den verwendeten Kommunikationstechnologien ist die Cybersicherheit ein wesentlicher Bestandteil von V2X. AutoCrypt V2X ist eine Sicherheitslösung, die sich in V2X-Chipsätze einbettet und das V2X-System sowohl mit Authentifizierungs- als auch Datenverschlüsselungstechnologien schützt (Autocrypt, 2021).
Laut Erhart (2019) wird der Mobilfunk (3G/4G, zukünftig 5G) im Fernverkehr eingesetzt werden. Die C-ROADS-Initiative, in der 18 EU-Mitgliedsstaaten zum Thema C-ITS zusammenarbeiten, strebt nicht nur eine europaweite Harmonisierung und Weiterentwicklung von C-ITS an, sondern auch die Definition der notwendigen Schnittstellen und Datenformate für diese Langstreckenlösung im Mobilfunkbereich. Die ASFINAG ist in diesen Bereichen ein führendes Mitglied der C-ROADS-Initiative und wird beide Kommunikationsarten bei der Umsetzung berücksichtigen.
Die nächste Generation der Kommunikationstechnologie könnte von Unternehmen wie Starlink oder Kuiper initiiert werden, wenn es ihnen gelingt, LEO-Konstellationen aufzubauen (Techbook, 2020). Starlink ist ein Teilunternehmen von Spacex und versucht, ein zusammenhängendes Internet-Netzwerk mit Tausenden von Satelliten aufzubauen, um Hochgeschwindigkeits-Internet auf der ganzen Welt zu liefern (Sheetz, 2021). Starlink-Satelliten sind mehr als 60 Mal näher an der Erde als herkömmliche Satelliten, was zu geringeren Latenzzeiten führt. Starlink eignet sich ideal für Gebiete auf der Welt, in denen die Konnektivität normalerweise eine Herausforderung darstellt (Starlink, n.d.). Allerdings stellen dicht besiedelte städtische Gebiete ein Problem dar (Holland, 2021). Derzeit befinden sich 1100 SpaceX-Satelliten im All, um den globalen Internetdienst aufzubauen. In den kommenden Jahren sollen mehrere tausend weitere Satelliten hinzukommen. Wie “Golem” berichtet, sollen es in der vollen Ausbaustufe 12000 Satelliten sein (finanzen.net, 2021). Starlink hat bereits mehr als 500.000 Bestellungen für seinen Satelliten-Internetdienst erhalten. Während Konkurrenten wie OneWeb oder Amazons Project Kuiper hinterherhinken, schafft SpaceX mit Starlink immer mehr Fakten (Holland, 2021). Satelliteninternet ist jedoch für Flugzeuge, Schiffe, große Lastwagen und Wohnmobile gedacht. Für PKWs sind sie noch nicht geeignet, da die Endgeräte dafür einfach viel zu groß sind (Musk, 2021).
Außerdem warnen Forscher:innen vor einigen Folgen für die Astronomie, die dieses Satellitensystem mit sich bringt. Zu den Nachteilen gehört eine kürzere effektive Betriebszeit der Teleskope (aufgrund von Satelliten, die bei Beobachtungen im Weltraum dazwischen sein können), ein höheres Potenzial für Kollisionen mit Forschungsinfrastrukturen, die Erzeugung von Trümmerteilen in der Umlaufbahn und ein erhöhter Bedarf an kostspieligen Ausweichmanövern von Raumschiffen während Weltraummissionen (Traxler & Rennert, 2020).
Relevante Initiativen in Österreich
DSRC-Module werden in Österreich bereits für die LKW-Mautabrechnung eingesetzt. Rund 152.000 Fahrzeuge haben im Jahr 2018 in Österreich über die Toll Collect OBU rund 190 Millionen Euro an Mauteinnahmen generiert. Das DSRC-Modul arbeitet auf Mikrowellenbasis und löst beim Passieren einer Mautstation auf österreichischen Autobahnen und Schnellstraßen eine Mauttransaktion aus, die dann von der Mautstation zur Abrechnung an das Rechenzentrum der ASFINAG übermittelt wird. Die fest im LKW installierte Toll Collect On-Board-Unit zeichnet sich durch hohe Verfügbarkeit und Stabilität aus. In Deutschland erfolgt die Mauterhebung mit der OBU weiterhin über Satellit.
Eine weitere aktuelle Anwendung von DSRC ist die Fernabfrage von Fahrtenschreiberdaten durch Kontrollbehörden. Seit dem 15. Juni 2019 müssen neue LKW und Busse über 3,5t hzGG mit einem “Smart Tacho” ausgestattet sein, der dies ermöglicht (WKÖ, 2019). Derzeit gibt es zwei C-ITS-Testumgebungen: eine rund um Wien und eine bei Graz. Geplant ist eine Ausweitung ab dem Jahr 2020. Zunächst sollen der Korridor Salzburg - Wien, die A2 um Graz und ausgewählte Grenzgebiete abgedeckt werden.
Auf europäischer Ebene hat sich eine Gemeinschaft von Straßenbetreibern, Fahrzeug- und Landmaschinenherstellern, Städten sowie Industrie- und Telekommunikationsunternehmen zu einer Interessengruppe namens “C-ITS Deployment Group” zusammengeschlossen. Die Mitglieder dieser Gruppe setzen sich für einen koordinierten C-ITS Einsatz in Europa ein, d.h. C-ITS Dienste sollen in ganz Europa gleich aussehen und von allen Fahrzeugen verstanden werden (Erhart, 2019).
Auswirkungen in Bezug auf die Ziele für nachhaltige Entwicklung (SDGs)
| Ebene der Auswirkungen | Indikator | Richtung der Auswirkungen | Beschreibung des Ziels & SDG | Quelle |
|---|---|---|---|---|
| Systemisch | Kontinuierliche Entwicklung der Kommunikationstechnologien | + | Innovation und Infrastruktur (9) | Techbook, 2020; Autotalks Ltd., n.d.; Salvo et al., 2017 |
| Systemisch | Neue Initiativen und Interessengruppen werden gegruendet | + | Partnerschaften und Kooperationen (17) | Erhart, 2019 |
Technologie- und gesellschaftlicher Bereitschaftsgrad
| Stand der Technologiebereitschaft | Gesellschaftlicher Bereitschaftsgrad |
|---|---|
| 5-8 | 6-8 |
Offene Fragen
- Welche alternativen Lösungen gibt es, um DSRC und C-V2X so zu verbinden, dass sie miteinander kompatibel sind?
Weitere links
Referenzen
- Annu, Kaushik, D., & Gupta, A. (2021). Ultra-secure transmissions for 5G-V2X communications. Materials Today: Proceedings. https://doi.org/10.1016/j.matpr.2020.12.130
- Autocrypt. (2021). AUTOCRYPT - DSRC vs. C-V2X: A Detailed Comparison of the 2 Types of V2X Technologies. https://www.autocrypt.io/blog-post/dsrc-vs-c-v2x-detailed-comparison
- Autotalks Ltd. (n.d.). C-V2X vs DSRC | Get Your Facts Straight on Cellular V2X, LTE-V and LTE-V2X Autotalks. Available at: https://www.auto-talks.com/technology/dsrc-vs-c-v2x-2/ [Accessed: 4 May 2021]
- Erhart, J. (2019, November 28). Vernetzte Autos, intelligenter Verkehr: Was C-ITS ist, was es kann und wem es nutzt.Available at: https://blog.asfinag.at/technik-innovation/c-its-vernetzte-autos-intelligenter-verkehr/ [Accessed: 4 May 2021]
- Fillenberg, S. (2017, December 18). Cellular V2X: Continental Successfully Conducts Field Trials in China. Continental Press Release. https://www.continental.com/en/press/press-releases/2017-12-18-cellular-v2x-116994
- finanzen.net. (2021, May 5). Internet aus dem All: Internetsparte von SpaceX: Starlink bald in Wohnmobilen, Schiffen und Flugzeugen? | Nachricht | finanzen.net. https://www.finanzen.net/nachricht/geld-karriere-lifestyle/internet-aus-dem-all-internetsparte-von-spacex-starlink-bald-in-wohnmobilen-schiffen-und-flugzeugen-9905140
- Gettman, D. (2020, June 3). DSRC and C-V2X: The Future of Connected Vehicles | Kimley-Horn. https://www.kimley-horn.com/news-insights/dsrc-cv2x-comparison-future-connected-vehicles/
- Hajiyat, Z. R. M., Ismail, A., Sali, A., & Hamidon, M. N. (2021). Antenna in 6G wireless communication system: Specifications, challenges, and research directions. Optik, 231(February), 166415. https://doi.org/10.1016/j.ijleo.2021.166415
- Holland, M. (2021, May 5). Starlink: Schon 500.000 Vorbestellungen für Satelliten-Internet von SpaceX | heise online. https://www.heise.de/news/Starlink-Schon-500-000-Vorbestellungen-fuer-Satelliten-Internet-von-SpaceX-6036732.html
- IEEE. (2014). IEEE Guide for Wireless Access in Vehicular Environments (WAVE) - Architecture. IEEE Std 1609.0-2013, 1–78. https://doi.org/10.1109/IEEESTD.2014.6755433
- Kang, S., Han, S., Cho, S., Jang, D., Choi, H., & Choi, J.-W. (2016). High speed CAN transmission scheme supporting data rate of over 100 Mb/s. IEEE Communications Magazine, 54(6), 128–135. https://doi.org/10.1109/MCOM.2016.7498099
- Mannoni, V., Berg, V., Sesia, S., & Perraud, E. (2019). A comparison of the V2X communication systems: ITS-G5 and C-V2X. IEEE Vehicular Technology Conference, 2019-April. https://doi.org/10.1109/VTCSpring.2019.8746562
- Musk, E. (2021, March 7). Elon Musk auf Twitter. https://twitter.com/elonmusk/status/1369051431903268865?ref_src=twsrc%5Etfw%7Ctwcamp%5Etweetembed%7Ctwterm%5E1369051431903268865%7Ctwgr%5E%7Ctwcon%5Es1
- Nitika, Rana, A., Kumar, V., & Awasthi, A. M. (2021). Effect of dopant concentration and annealing temperature on electric and magnetic properties of lanthanum substituted CoFe2O4 nanoparticles for potential use in 5G wireless communication systems. Ceramics International. https://doi.org/10.1016/j.ceramint.2021.04.077
- Rath, M., Pati, B., & Pattanayak, B. K. (2019). An Overview on Social Networking: Design, Issues, Emerging Trends, and Security. In Social Network Analytics (pp. 21–47). Elsevier. https://doi.org/10.1016/b978-0-12-815458-8.00002-5
- Salvo, P., Turcanu, I., Cuomo, F., Baiocchi, A., & Rubin, I. (2017). Heterogeneous cellular and DSRC networking for Floating Car Data collection in urban areas. Vehicular Communications, 8, 21–34. https://doi.org/10.1016/j.vehcom.2016.11.004
- Sattiraju, R., Wang, D., Weinand, A., & Schotten, H. D. (2020). Link level performance comparison of C-V2X and ITS-G5 for vehicular channel models. ArXiv, March.
- Sheetz, M. (2021, May 4). SpaceX: Over 500,000 orders for Starlink satellite internet service. Available at: https://www.cnbc.com/2021/05/04/spacex-over-500000-orders-for-starlink-satellite-internet-service.html [Accessed: 4 May 2021]
- Starlink. (n.d.). Starlink. Available at: https://www.starlink.com/ [Accessed: 6 May 2021]
- Techbook. (2020, November 16). LTE, 4G und 5G: Die Unterschiede zwischen den Mobilfunkstandards.Available at: https://www.techbook.de/mobile/lte-4g-unterschied-mobil-smartphone [Accessed: 4 May 2021]
- Traxler, T., & Rennert, D. (2020, February 17). Starlink: Elon Musks Satellitenflotte in der Kritik - Raum - derStandard.at › Wissenschaft.Available at: https://www.derstandard.at/story/2000114681438/starlink-elon-musks-satellitenflotte-in-der-kritik [Accessed: 4 May 2021]
- WKÖ. (2019). Ausrüstungspflicht von neuen lkw und omnibussen mit einem „smart tacho“ ab 15. Juni 2019. Available at: https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&ved=2ahUKEwiyka_Xs7XwAhXytYsKHTq_AJ0QFjADegQIBBAD&url=https%3A%2F%2Fwww.wko.at%2Fbranchen%2Ftransport-verkehr%2Fausruestungspflicht-smart-tacho.pdf&usg=AOvVaw12-xLPvw33KN9gvYKy51tn [Accessed: 4 May 2021]
- Zhao, X., Jing, S., Hui, F., Liu, R., & Khattak, A. J. (2019). DSRC-based rear-end collision warning system – An error-component safety distance model and field test. Transportation Research Part C: Emerging Technologies, 107, 92–104. https://doi.org/10.1016/j.trc.2019.08.002
12.2 Big data Lebenszyklus
Definition
“Big Data bezieht sich auf große Datensätze, die heterogene Formate umfassen: strukturierte, unstrukturierte und semistrukturierte Daten. Big Data ist von komplexer Natur und erfordert leistungsstarke Technologien und fortschrittliche Algorithmen. Daher können die traditionellen statischen Business Intelligence-Tools bei Big Data-Anwendungen nicht mehr effizient sein” (Oussous et al., 2018). Big Data ist typischerweise durch die 3Vs (Volume, Velocity und Variety) gekennzeichnet, wie im Thema Big Data Tools beschrieben. Im Verkehrskontext sind die wichtigsten Quellen von Big Data:
- Fahrerassistenzsysteme und instrumentierte Fahrzeuge, die die Fahrzeugumgebung und das Fahrverhalten ständig überwachen
Yuan et al. (2015) behauptet, dass vernetzte Fahrzeuge sogar 30 GB an Daten pro Tag produzieren könnten. - Informationssysteme für Reisende
- Straßenbetrieb und -management wie variable Geschwindigkeitsbegrenzungen und dynamische Beschilderungssysteme
- Verkehrsdaten
Zum Beispiel [Echtzeit-Verkehrsinformationen und -überwachung],(#traffic_info_monitoring) die strukturierte und unstrukturierte Daten wie JPG, JSON, GPS, PDF, Bilder, Videos und Beiträge in sozialen Medien erzeugen können (Kemp et al., 2015) - Notfall- und Störfallmanagement
Die in Neilson et al. (2019) zusammengefasste Literatur zeigt die folgende Verwendung von Big Data im Verkehrskontext:
| Verwendete Big-Data-Systeme | Zwecke der Big-Data-Analyse | Arten der erfassten Daten | Aktuelle Chancen und Herausforderungen |
|---|---|---|---|
| ITS, Hadoop, MapReduce, Batch- und Stream-Datenverarbeitung, NoSQL | Stadtplanung, Analyse von Kollisionen und Beinaheunfaellen, Verkehrsueberlastung, Sicherheit, Optimierung | Geschwindigkeit, Standort, Video, Bild, Verkehrsintensitaet, soziale Medien, Crowdsourcing, maschinelles Lernen, historische, Echtzeit-, praediktive, visuelle, Video-/Bildanalyse | Datenerhebung, -qualitaet, -speicherung, -verarbeitung, Datenschutz, Sicherheit, vernetzte und automatisierte Fahrzeuge |
Ein weiterer wichtiger Teil von Big Data ist der Lebenszyklus, auch Informationslebenszyklus genannt, der als der Zeitraum definiert ist, in dem die Daten im System vorhanden sind. Dieser Lebenszyklus umfasst alle Phasen, die die Daten von der ersten Erfassung an durchlaufen (Talend.com, 2021). In der aktuellen Literatur werden verschiedene Modelle vorgeschlagen, die von der Art der Daten und dem jeweiligen Bereich abhängen. Nichtsdestotrotz weisen sie einige Ähnlichkeiten auf, und die meisten Phasen werden von den meisten Datenzyklusmodellen geteilt. Nach Arras & Souissi (2018) sind die wichtigsten Phasen des Big Data Lifecycle folgende:
- Planung: Eine detaillierte Beschreibung, wie Daten während ihres Lebenszyklus genutzt, verwaltet und zugänglich gemacht werden sollen
- Management: Umfasst alle operativen Phasen, in denen die Daten direkt bearbeitet werden
- Sammlung: Sie besteht aus dem Empfang der Rohdaten verschiedener Typen und der Durchführung der für ihre Organisation erforderlichen Umwandlungen und Änderungen. Die Bereinigung der in Echtzeit empfangenen Daten spart Rechenzeit und Speicherplatz. Die Datenqualität muss auf dieser Ebene durchgeführt werden, da sie eine Optimierung des gesamten Datenverarbeitungskreislaufs ermöglicht.
- Integration: In dieser Phase geht es darum, ein kohärentes Muster von Daten aus mehreren unabhängigen, verteilten und heterogenen Informationsquellen bereitzustellen, um den Benutzer:innen den Zugriff und die Abfrage dieser Daten zu erleichtern, als ob sie auf eine einzige Datenquelle zugreifen würden
- Filtern: Besteht in der Einschränkung des großen Datenstroms, um irrelevante Daten oder Fehler zu entfernen
- Anreicherung: Bei der Datenanreicherung werden strukturelle oder hierarchische Änderungen an den empfangenen Daten vorgenommen. Sie ermöglicht das Hinzufügen von Informationen zu den gesammelten Daten, um deren Qualität zu verbessern.
- Analyse: In dieser Phase werden die Daten ausgewertet und analysiert, um Schlussfolgerungen und Interpretationen für die Entscheidungsfindung zu ziehen
- Zugang: In dieser Phase geht es um die Kommunikation/Interaktion mit den Datenkonsument:innen
- Visualisierung: Sie besteht darin, die Ergebnisse der Analyse in einer übersichtlichen Form darzustellen, so dass die Entscheidungsträger:innen diese Ergebnisse leicht verstehen und fundierte Entscheidungen treffen können
- Speicherung: Betrifft alle anderen Phasen des Zyklus und ermöglicht die Speicherung der Daten während ihres gesamten Lebenszyklus, um eine kontinuierliche Rückverfolgbarkeit der Daten in jeder Phase des Zyklus zu gewährleisten
- Vernichtung: In dieser Phase werden die Daten entsorgt, wenn sie erfolgreich genutzt wurden und somit nutzlos und ohne Mehrwert sind.
- Archivierung: Besteht aus einer Implementierung von Datensicherheit und Vertraulichkeit
Darüber hinaus haben Djahel et al. (2014) einen Big-Data-Lebenszyklus in Bezug auf Verkehrsmanagementsysteme (TMS) vorgeschlagen, der in Abbildung 12.2 dargestellt ist.
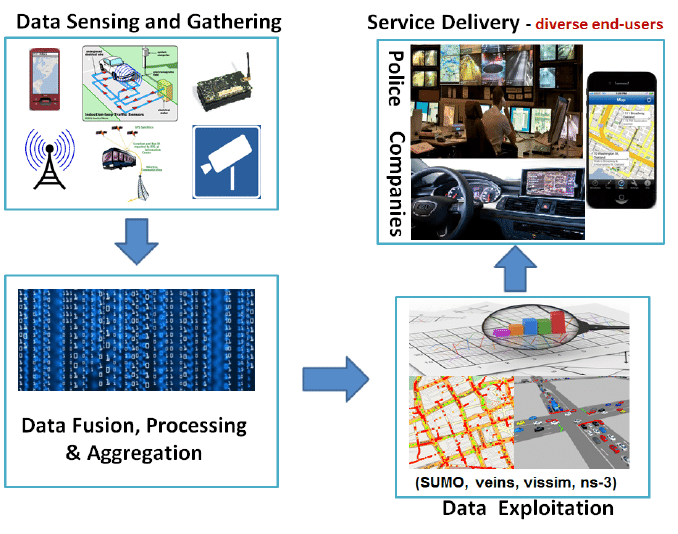
Figure 12.2: Lebenszyklus von Big Data im intelligenten Verkehrswesen (Djahel et al., 2014)
In der ersten Phase der Datenerfassung und -sammlung (Data Sensing and Gathering, DSG) werden die Verkehrsdaten überwacht und gesammelt, um Informationen über das Verkehrsaufkommen, Zwischenfälle, die Auslastung oder die Geschwindigkeit zu erhalten. Die gesammelten Daten fließen später in die zweite Phase der Datenfusion, -verarbeitung und -aggregation ein, in der die relevanten Informationen aus den Rohdaten extrahiert werden. In der dritten Phase, der Datenauswertung, werden die verarbeiteten Daten zur Berechnung optimaler Routen, zur Erstellung von Prognosen und zur Erstellung von Verkehrsstatistiken verwendet. In der Phase der Bereitstellung von Diensten schließlich teilt das TMS das Wissen mit den Endnutzer:innen wie Fahrer:innen, Behörden oder Fahrgästen über eine Vielzahl von Geräten wie Smartphones oder Bordeinheiten von Fahrzeugen.
Wichtige Interessensgruppen
- Betroffene: Fahrgäste, Fahrer:innen, auf ITS spezialisierte Unternehmen
- Verantwortliche: Nationale Regierungen, Technologieunternehmen, auf IVS spezialisierte Unternehmen, Verkehrsunternehmen, Entwickler von Verkehrssoftware
Aktueller Stand der Wissenschaft und Forschung
Wie bereits erwähnt, gibt es in der Literatur verschiedene Modelle des Lebenszyklus von Big Data, die über das von Arras & Souissi (2018) vorgeschlagene Modell des Smart Data Lifecycle (DLC) hinausgehen. Nach Alshboul et al. (2015) beispielsweise umfasst der Lebenszyklus von Big Data vier Phasen:
- Datenerfassung
Daten aus verschiedenen Quellen kommen in unterschiedlichen Formaten: Strukturiert, halbstrukturiert und unstrukturiert. - Speicherung der Daten
Die gesammelten Daten werden gespeichert und für die Verwendung in der nächsten Phase vorbereitet. Da die gesammelten Daten sensible Informationen enthalten können, ist es wichtig, bei der Datenspeicherung ausreichende Vorsichtsmaßnahmen zu treffen (z. B. Permutation, Anonymisierung). - Datenanalytik
Die Daten werden analysiert, um nützliches Wissen zu generieren. In dieser Phase werden Data-Mining-Methoden wie Clustering, Klassifizierung und Assoziationsregel-Mining eingesetzt. - Schaffung von Wissen
Die Ergebnisse der Analysen werden von den Entscheidungsträger:innen genutzt.
Demchenko et al. (2014) schlagen ein Big Data Lifecycle Management (BDLM) Modell vor, das aus sechs Phasen besteht:
- Datenquelle
- Datenerfassung
- Datenbereinigung (Filterung, Klassifizierung)
- Datenanalytik
- Visualisierung von Daten
- Anwendung der Datenanalyse
Aktueller Stand der praktischen Umsetzung
The typical management tools, techniques and software used Die typischen Verwaltungstools, -techniken und -software für die Datenverarbeitung sind Google BigTable, Simple DB, Not Only SQL (NoSQL), Data Stream Management System (DSMS), MemcacheDB und Voldemort. Es werden jedoch ständig neue Anwendungen mit höheren Fähigkeiten entwickelt, um den Anforderungen von Big Data gerecht zu werden (Chen et al., 2014). Hadoop zum Beispiel wurde speziell für die Verwaltung von Big Data in verschiedenen Phasen ihres Lebenszyklus entwickelt. Es handelt sich um ein Open-Source-Software-Framework, das die Verarbeitung großer Datensätze in Computerclustern mithilfe einfacher Programmiermodelle wie Google MapReduce ermöglicht (Khan et al., 2014). Hadoop kann extrem große Datenmengen mit unterschiedlichen Strukturen (oder ohne jegliche Struktur) verarbeiten. Es wird in der Regel auf große Datenmengen angewandt und ermöglicht die Verarbeitung von Daten, die zuvor schwer zu verwalten und zu analysieren waren.
Ein Beispiel aus der Praxis: Big Data in Verbindung mit dem Internet der Dinge (IoT) wird von Data Mill North’s National Public Transport Access Nodes (NaPTAN) im Vereinigten Königreich genutzt, um den Fahrgästen Verkehrsinformationen in Echtzeit zu liefern. So nutzen Bahnbetreiber bereits Big Data, um Informationen über die Verfügbarkeit von Sitzplätzen in Echtzeit anzubieten (Rayner, 2017).
Relevante Initiativen in Österreich
Auswirkungen in Bezug auf die Ziele für nachhaltige Entwicklung (SDGs)
| Ebene der Auswirkungen | Indikator | Richtung der Auswirkungen | Beschreibung des Ziels & SDG | Quelle |
|---|---|---|---|---|
| Systemisch | Erhoehte Sicherheit fuer Fahrer:innen und Fahrgaeste oeffentlicher Verkehrsmittel | + | Gesundheit und Wohlbefinden (3) | Rayner, 2017 |
| Systemisch | Erhoehter Energieverbrauch | - | Oekologische Nachhaltigkeit (7,12-13,15) | Lovell, 2018 |
| Systemisch | Potenzial fuer eine zuverlaessigere und transparentere Partnerschaft entlang der Lieferkette | + | Partnerschaften und Kooperationen (17) | Robins, 2021 |
Technologie- und gesellschaftlicher Bereitschaftsgrad
| Stand der Technologiebereitschaft | Gesellschaftlicher Bereitschaftsgrad |
|---|---|
| 5-9 | 6-9 |
Offene Fragen
- Wie lässt sich das Potenzial für Cyberangriffe verringern und wie können die Sicherheitsmethoden verbessert werden?
- Wie kann das Problem, dass Daten in deutschsprachigen Ländern als Bedrohung angesehen werden, gemildert werden?
Referenzen
- Alshboul, Y., Nepali, R. K., & Wang, Y. (2015, August). Big Data LifeCycle: Threats and Security Model. In AMCIS.
- Chen, M., Mao, S., & Liu, Y. (2014). Big data: A survey. Mobile networks and applications, 19(2), 171-209.
- Demchenko, Y., De Laat, C., & Membrey, P. (2014, May). Defining architecture components of the Big Data Ecosystem. In 2014 International conference on collaboration technologies and systems (CTS) (pp. 104-112). IEEE.
- Djahel, S., Doolan, R., Muntean, G. M., & Murphy, J. (2014). A communications-oriented perspective on traffic management systems for smart cities: Challenges and innovative approaches. IEEE Communications Surveys & Tutorials, 17(1), 125-151.
- El Arass, M., & Souissi, N. (2018, October). Data lifecycle: From big data to smartdata. In 2018 IEEE 5th international congress on information science and technology (CiSt) (pp. 80-87). IEEE.
- Kemp, G., Vargas-Solar, G., Da Silva, C. F., & Ghodous, P. (2015, May). Aggregating and managing big realtime data in the cloud-application to intelligent transport for smart cities. In Proceedings of the 1st international conference on vehicle technology and intelligent transport systems (pp. 107-112).
- Khan, N., Yaqoob, I., Hashem, I. A. T., Inayat, Z., Mahmoud Ali, W. K., Alam, M., … & Gani, A. (2014). Big data: survey, technologies, opportunities, and challenges. The scientific world journal, 2014.
- Neilson, A., Daniel, B., & Tjandra, S. (2019). Systematic review of the literature on big data in the transportation domain: Concepts and applications. Big Data Research, 17, 35-44.
- Oussous, A., Benjelloun, F. Z., Lahcen, A. A., & Belfkih, S. (2018). Big Data technologies: A survey. Journal of King Saud University-Computer and Information Sciences, 30(4), 431-448. Rayner, T. (2017). Deriving Transport Benefits from Big Data and the Internet of Things in Smart Cities. Available at: https://www.womblebonddickinson.com/uk/insights/articles-and-briefings/deriving-transport-benefits-big-data-and-internet-things-smart [Accessed: 12 August 2021]
- Robins, C. (2021). WHY BIG DATA IS SO IMPORTANT TO THE TRANSPORTATION INDUSTRY Available at: https://www.robinsconsulting.com/why-big-data-is-so-important/ [Accessed: 12 August 2021]
- Talend.com (2021). Data Lifecycle Management (Definition and Framework). Available at: https://www.talend.com/resources/data-lifecycle-management/ [Accessed: 12 August 2021].
- Yuan, W., Deng, P., Taleb, T., Wan, J., & Bi, C. (2015). An unlicensed taxi identification model based on big data analysis. IEEE Transactions on Intelligent Transportation Systems, 17(6), 1703-1713.
12.3 Big-Data-Tools für die Kartierung und Vorhersage des Reiseverhaltens
Synonyme
Anwendungsprogrammierschnittstelle (API - application programming interface)
Definition
(Echtzeit-)Verkehrskartierung
Die Verkehrskartierung erfolgt zum einen mit Verkehrssensoren und zum anderen mit Smartphone-Daten. Staatliche Verkehrsämter haben damit begonnen, solarbetriebene Verkehrssensoren an Hauptverkehrsstraßen im ganzen Land zu installieren, um die aktuelle Verkehrssituation zu erfassen, Planungsstatistiken zu erstellen, die Reaktionszeiten bei Unfällen zu verbessern und den Verkehrsfluss zu erhöhen. Die Daten werden mit verschiedenen Arten von Verkehrssensoren erfasst. In den letzten Jahren haben sich drei oberirdische Typen durchgesetzt: Radar, Aktiv-Infrarot und Laserradar. Die Radarsensorik gibt es bereits seit dem Zweiten Weltkrieg, als sie dem Militär half, feindliche Schiffe in der Luft und auf See zu verfolgen. Die heutige Technologie ermöglicht es jedem dieser Geräte, mehrere Verkehrsspuren gleichzeitig zu überwachen (Machay, n.d.).
Google Maps ist ein wichtiger Akteur auf dem Gebiet der Navigation und Verkehrskartierung. Bis März 2012 gab es keine Verkehrsfunktion - man konzentrierte sich lediglich darauf, die Nutzer:innen von A nach B zu bringen. Es gab zwar eine Funktion, die anzeigte, wie sehr der Verkehr eine:n Fahrer:in aufhalten würde, aber es gab keine Live-Daten. Damals wurden nur historische Daten verwendet, um zu zeigen, wie lange dieselbe Strecke “bei starkem Verkehr” dauern würde (NCTA, 2013).
Dann wurde mit den Verkehrsbehörden eine Vereinbarung getroffen, einerseits die von den Sensoren generierten Daten gemeinsam zu nutzen, und andererseits konnten Smartphone-Daten für Echtzeitdaten verwendet werden. Die Daten der Verkehrssensoren der Verkehrsbehörden ermöglichten es Google, seine Verkehrsdienste zu erweitern, während die Verkehrsbehörden einen Teil der Kosten für die Sensoren übernehmen konnten. Durch die Zusammenarbeit mit verschiedenen Verkehrsbehörden erhielt Google aktuelle Informationen über Staus auf Autobahnen und Hauptverkehrsstraßen, war aber kaum in der Lage, den Verkehr auf kleineren Landstraßen und in Wohngebieten zu überwachen. Die aktuellen Verkehrsdaten werden hauptsächlich über GPS-fähige Mobiltelefone gesammelt, auf denen die Anwendung Google Maps läuft. Diese übertragen kontinuierlich den Standort und die Geschwindigkeit von allen Nutzer:innen in Echtzeit an Google. Mithilfe einer als “Crowdsourcing” bekannten Technik kombiniert Google die von Tausenden von aktiven Mobiltelefonen gelieferten Informationen, um zu ermitteln, wie schnell der Verkehr an einem bestimmten Ort fließt (Machay, n.d.). Was den Datenschutz betrifft, so behauptet Google, dass die Nutzer:innen in den Einstellungen ihres Telefons entscheiden können, ob sie ihre Reisedaten mit Google teilen wollen oder nicht. Das Unternehmen weist darauf hin, dass es versucht, die Informationen zu schützen (Google selbst weiß nicht einmal, welche Daten von welchem Auto stammen, und es schneidet die ersten und letzten Minuten jeder Fahrt ab, um sie noch unkenntlicher zu machen). Wenn die Nutzer:innen sich dafür entscheiden, tragen sie dazu bei, einen hilfreichen Dienst zu erbringen - die Nutzer:innen erhalten realistischere Schätzungen über die Dauer ihrer Fahrt und können sich besser auf den Verkehr einstellen. Mike Dobson (Präsident von Telemapics) stellt sich ein Zukunftsszenario vor, in dem Google 5 % der Nutzer:innen Umleitungen vorschlagen könnte, um entweder Verkehrsstaus zu entschärfen oder die Wahrscheinlichkeit von Verspätungen zu verringern. Zhan Guo, Professor für Verkehrspolitik an der New York University, sagt, dass es schwierig sein wird, Ratschläge zur Umleitung des Verkehrs zu geben, da Fahrer:innen, die eine Strecke täglich fahren, am besten wissen, was am längsten dauert. Wenn es nur wenige andere Wege gibt, um von A nach B zu kommen, ist es sinnlos, Alternativen vorzuschlagen, denn jeder wird sich beeilen, eine andere Straße zu verstopfen. Ein Algorithmus, der genau die richtige Menge an Verkehr umleitet, ist seiner Meinung nach wahrscheinlich noch einige Jahre entfernt (NCTA, 2013).
Aufgrund der zunehmenden Verbreitung von Mobiltelefonen mit eingebauten Standort- und Bewegungssensoren in der Bevölkerung können umfangreiche und dynamische Daten gesammelt werden. Mobiltelefondaten ermöglichen eine noch nie dagewesene Abdeckung der Bevölkerung und des geografischen Gebiets (Wang et al., 2018). Die Nachteile dieser Systeme bestehen darin, dass Radarsensoren keine liegengebliebenen Fahrzeuge erkennen können, da sie keine Objekte erkennen können, die sich nicht bewegen. Aktiv-Infrarot- und Laser-Radarsensoren funktionieren bei dichtem Nebel oder Schneetreiben nicht richtig. Und die Genauigkeit des Crowdsourcing kann beeinträchtigt werden, wenn nicht genügend Mobiltelefone Daten für ein bestimmtes Gebiet liefern (Machay, n.d.).
Verkehrsprognose
Um die Verkehrsnachfrage zu prognostizieren, werden Informationen über die Vergangenheit, den Zustand des Verkehrssystems und sein externes System berücksichtigt. Verkehrsprognosemethoden lassen sich je nach mathematischen Methoden und Berechnungsverfahren in verschiedene Typen unterteilen, z. B. qualitativ und quantitativ, linear und nichtlinear, dynamisch und statisch, aggregiert und disaggregiert (Zhao et al., 2018).
Seit den 1950er Jahren dominiert das “Vier-Stufen-Modell” die Methoden der Reisebedarfsprognose. Seit den 1970er Jahren haben tätigkeitsbasierte Prognosemethoden mehr Aufmerksamkeit auf sich gezogen.
Reiseprognosemethoden
Trip-basierte Methoden der Reisebedarfsprognose unterteilen die Einheit der Reiseprognose in der Regel in ein “Aggregat” (Verkehrsgebiet) und konzentrieren sich auf die Bevölkerung und Flächennutzung des Verkehrsgebiets. Diese Methoden berücksichtigen im Allgemeinen die räumliche Koordination auf Stadtebene, ignorieren aber die tatsächlichen Reisebedürfnisse und Empfindungen der einzelnen Einwohner:innen. Aufgrund der geringen Flexibilität und des geringen Verfeinerungsgrads der Vorhersageergebnisse können diese Methoden daher leicht zu Problemen mit einer ungleichmäßigen Verkehrsverteilung führen (Qin et al., 2013).
Es gibt mehrere reisebasierte Prognosemethoden. Zhao et al. (2018) führen 5 grundlegende Methoden mit Vorteilen und Einschränkungen auf:
- Graue Systemtheorie (GST)
In diesem System sind einige Informationen bekannt und einige Informationen unbekannt. Sie ist für kurzfristige Prognosen auf der Grundlage herkömmlicher Umfragedaten fast unmöglich zu verwenden. - Kalman-Filterung (KF)
Sie kann den Zustand des dynamischen Systems aus einer Reihe von unvollständigen und verrauschten Messungen schätzen. - Chaostheorie (CT)
Sie befasst sich mit der geordneten Struktur und Regelmäßigkeit von scheinbar zufälligen Phänomenen in dynamischen Systemen. Es wird jedoch eine große Menge an Verkehrsüberwachungsdaten als Trainings- oder Entscheidungsmuster benötigt. Aufgrund der Datenerfassung, -eingabe, -übertragung und -speicherung erfordern diese Methoden eine langwierige Vorverarbeitung der Daten und haben nur begrenzte Echtzeitfähigkeiten. - Künstliches Neuronales Netz (ANN)
Ein mathematisches Modell, das die Struktur und Funktion von biologischen neuronalen Netzen nachahmt. Auch hier sind große Mengen an Verkehrsüberwachungsdaten und eine langwierige Vorverarbeitung der Daten erforderlich. - Support-Vektor-Maschine (SVM)
Eine Methode des maschinellen Lernens.
Aktivitätsbasierte Prognosemethoden
Aktivitätsbasierte Prognosemethoden sind eine Art von disaggregierten Prognosemethoden, die sich auf die Gründe für die Reisen von Einzelpersonen und das “Aktivitäts-Reise”-Modell konzentrieren und Einzelpersonen als Forschungsobjekte verwenden. Diese Methoden untersuchen auch die kausale Beziehung zwischen Aktivitäten und Reisen. Beispiele hierfür sind das Multi-Agent-System-Modell (MAS) und das Multinomial-Logit-Modell (MNL). Aktivitätsbasierte Prognosen erfordern eine große Menge an individuellen Stichprobendaten (Zhao et al., 2018). Aufgrund der begrenzten Datenverarbeitungskapazität werden sie in erster Linie für den Modussplit und nur selten für die Prognose der Verkehrsentwicklung und -verteilung verwendet (P. Wang et al., 2013).
Große Daten
Big Data bezieht sich auf Daten, die ab einem bestimmten Entwicklungsstadium nicht mehr mit herkömmlichen Datenbanksoftware-Tools erfasst, gespeichert, analysiert oder verarbeitet werden können (Manyika et al., 2011). Es gibt einige Merkmale und Eigenschaften von Big Data, die als die Vs des Big Data Management bezeichnet werden (Al Nuaimi et al., 2015). Nach Fan & Bifet (2013) gehören dazu die 3 Haupt-Vs (1, 2 und 3) und zwei weitere Vs:
- Volumen: bezieht sich auf den Umfang der aus allen Quellen erstellten Daten.
- Velocity (Geschwindigkeit): bezieht sich auf die Geschwindigkeit, mit der Daten erstellt, gespeichert, analysiert und verarbeitet werden.
- Variety (Vielfalt): bezieht sich auf die verschiedenen Arten von Daten, die erzeugt werden. Heutzutage ist es üblich, dass die meisten Daten unstrukturiert sind und sich nicht leicht kategorisieren oder tabellieren lassen.
- Variability (Unbeständigkeit): bezieht sich auf die Tatsache, dass sich die Struktur und Bedeutung der Daten ständig ändert, insbesondere bei Daten, die z. B. aus der Analyse natürlicher Sprache stammen.
- Value (Wert): bezieht sich auf den potenziellen Vorteil, den Big Data einem Unternehmen auf der Grundlage einer guten Sammlung, Verwaltung und Analyse von Big Data bieten kann.
Andere erwähnen einige weitere Vs von Big Data, die einige weitere Aspekte abdecken. Zum Beispiel die Volatilität, die sich auf die Aufbewahrungspolitik von strukturierten Daten aus verschiedenen Quellen bezieht. Validität bezieht sich auf die Korrektheit, Genauigkeit und Validierung der Daten. Veracity (Wahrhaftigkeit) bezieht sich auf die Stichhaltigkeit und Richtigkeit der gesammelten Daten und die Aussagekraft der aus den Daten generierten Ergebnisse für bestimmte Probleme (Al Nuaimi et al., 2015).
Weitere einzigartige Merkmale im Vergleich zu traditionellen Datenanalysemethoden sind: (1) die Datenquelle wird von den Beispieldaten auf die gesamten Daten ausgeweitet; (2) die Daten einer einzelnen Domäne werden auf die domänenübergreifenden Daten ausgeweitet; (3) die Big-Data-Analyse erforscht hauptsächlich die Beziehungen zwischen den Daten (Zhao et al., 2018).
Aufgrund des Fortschritts der verschiedenen Technologien haben das Volumen, die Vielfalt und die Verfügbarkeit von Daten rapide zugenommen. Im Jahr 2003 hatte die Menschheit fünf Exabyte (5 × 106 Terabyte) an Daten erzeugt (Sagiroglu & Sinanc, 2013). Im Jahr 2012 wurde die gleiche Datenmenge in nur zwei Tagen erzeugt (McAfee et al., 2012).
In der Vergangenheit wurden in Studien zur Straßenverkehrssicherheit meist manuell erfasste Daten (z. B. Daten aus handschriftlichen polizeilichen Unfallberichten) zusammen mit geschätzten statischen Verkehrsmengen verwendet. Die Installation von Detektoren und Sensoren, die rasche Verbreitung von IVS und das Aufkommen von CAV führten zu einem Anstieg der Datenmenge über Menschen, Fahrzeuge, Straßen und Umgebungen (Lian et al., 2020).
In der Vergangenheit stammten die Daten zur Erforschung des Reiseverhaltens größtenteils aus Reiseerhebungen, deren Erhebung kostspielig und veraltet ist. Dies hat die Datenerhebung eingeschränkt und den Fortschritt in der Reiseverhaltensforschung behindert (Liu et al., 2016). Im Zeitalter von Big Data können verschiedene neue Datenquellen genutzt werden, um traditionelle Umfragedaten zu ergänzen oder zu ersetzen und so die Reiseverhaltensforschung zu unterstützen. Einige Beispiele sind Daten aus Smartcard-Aufzeichnungen, GPS-basierte Taxi-Trajektorendaten und straßenseitige Sensordaten, wobei Mobiltelefondaten die am weitesten verbreitete und vielversprechendste Art sind (Yue et al., 2014). Es gibt zwei Hauptquellen für Mobiltelefondaten, die derzeit für die Reiseverhaltensforschung verwendet werden (Z. Wang et al., 2018):
- Mobiltelefonnetzdaten Hier werden RF-Signale (Radiofrequenz) verwendet, um den Standort von Mobiltelefonen zu bestimmen. Zu diesen RF-Signalen gehören Mobilfunknetzsignale, GPS, AGPS, WiFi und Bluetooth.
- Smartphone-Sensordaten Eingebaute Sensoren (Beschleunigungssensoren, Magnetsensoren und Kompasse) werden zur Überwachung des Bewegungsstatus von Mobiltelefonen verwendet. Verschiedene Arten von Daten werden von unterschiedlichen Organisationen mit unterschiedlichen Techniken für unterschiedliche Zwecke gesammelt. Im Allgemeinen befinden sich die Versuche zur Nutzung von Mobiltelefondaten in der Reiseverhaltensforschung im Jahr 2021 noch in einem frühen Stadium, und die laufende Forschung hat viele Einschränkungen in Bezug auf Forschungsthemen, angewandte Methoden und Ergebnisse. Allerdings gibt es auch einige revolutionäre Errungenschaften, die bisher erzielt wurden.
Die Rolle von Big Data im Verkehrsmanagement und bei der Analyse von Reisecharakteristika wurde von Forscher:innen breit diskutiert. Es gibt jedoch mehrere Probleme bei der Vorhersage der Verkehrsnachfrage. Vor allem aufgrund der Zufälligkeit des Reisens und der Offenheit des Verkehrssystems sind sowohl das Reiseverhalten der Menschen als auch die Verkehrsströme des Straßensystems mit Unsicherheit behaftet. Die Entwicklung von Big Data wird mit einer Phase mit kleinen Stichproben (1980er Jahre), über die Phase mit großen Stichproben (1990er Jahre) bis zur aktuellen Big-Data-Phase beschrieben. Anfangs gab es aufgrund begrenzter Datenerhebungsmethoden nur relativ wenige Verkehrsdaten, und die Modelle zur Vorhersage der Verkehrsnachfrage waren darauf ausgelegt, mit kleinen Stichproben eine bessere Vorhersageleistung zu erzielen. In den 1990er Jahren verbesserte sich die Verkehrsüberwachungstechnologie erheblich, und das Volumen der Verkehrsdaten nahm rasch zu. Seit Beginn des 21. Jahrhunderts haben jedoch einige Forschungsergebnisse gezeigt, dass die Vorhersagegenauigkeit durch eine Erhöhung der Stichprobenzahl nicht wesentlich verbessert wird. Die Genauigkeit der einzelnen Stichprobeninformationen wird als der eigentliche Schlüssel angeführt.
Durch Big Data haben sich die Verkehrsdaten von einem ursprünglichen statischen Einzeldatensatz zu einem Datensatz mit mehreren Quellen, mehreren Zuständen und mehreren Strukturen entwickelt, der sowohl statische als auch dynamische Daten kombiniert. Die Datenerfassung des gesamten Netzwerks umfasst neben den Verkehrsdaten (Verkehrsfluss, Flottenlänge, Fahrzeugtyp, Fahrtrichtung, Fahrzeit, Momentangeschwindigkeit, Fahrgeschwindigkeit) auch Attributdaten einzelner Personen oder Fahrzeuge. Die Zusammenarbeit zwischen der Verkehrsinformationszentrale und einem Mobilfunkbetreiber ist zur wichtigsten Form der Big-Data-Anwendung geworden. Die Datenerfassung für Kraftfahrzeuge erfolgt über GPS auf elektronischen Nummernschildern. Im Zeitalter von Big Data werden auch unstrukturierte Daten (Web-Click-Streams, Dokumente, soziale Netzwerke, das Internet der Dinge, Anrufprotokolle, Videos, Fotos) im Verkehrswesen verwendet, um das Reiseverhalten der Menschen zu untersuchen (Zhao et al., 2018).
Neue Trends in der Reisebedarfsprognose betreffen hauptsächlich die folgenden acht Aspekte (Zhao et al., 2018):
- Die Anzahl der Prognosestichproben hat sich deutlich erhöht
- Die Menge an Informationen und die Genauigkeit der einzelnen Stichproben haben sich deutlich erhöht
- Disaggregierte Methoden werden zunehmend erforscht und angewandt, und dem einzelnen Reisenden wird mehr Aufmerksamkeit geschenkt
- Aggregierte und disaggregierte Methoden werden integriert
- Die Kombination von Modellen ist zu einem Entwicklungstrend geworden
- Es gibt mehr Methoden und Ressourcen für Reiseprognosen auf Mikroebene
- Zufällige Verkehrsdaten werden vermieden und verkehrsfremde Daten (anstelle von Verkehrsdaten) werden für Prognosen verwendet
- Kostenbeschränkungen bei der Prognose der Verkehrsnachfrage werden wahrscheinlich beseitigt, so dass die Datenerhebung einfacher wird
Aufgrund der Grenzen aggregierter Methoden und der Skalierung von Verkehrszonen sind herkömmliche Methoden zur Prognose der Verkehrsnachfrage oft nicht genau genug, um die Nachfrage nach nicht motorisierten Fahrzeugen wie Fußgänger:innen und Radfahrer:innen zu prognostizieren. Mit der Umsetzung städtischer Strategien wie “grüner Verkehr”, “langsamer Verkehr” und “lebenswerte Stadt” besteht ein objektiver Bedarf, die Genauigkeit von Verkehrsprognosen für den Fußgänger:innen- und Radverkehr zu verbessern. Big-Data-Methoden können einen Weg dazu bieten (Zhao et al., 2018).
Wichtige Interessensgruppen
- Betroffene: Nutzer:innen von sozialen Medien und/oder Smartphones, Autofahrer:innen
- Verantwortliche: Nutzer:innen sozialer Medien und/oder von Smartphones, Autofahrer:innen, Forscher:innen, Verkehrsüberwachungsbehörden, Verkehrsagenturen
Aktueller Stand der Wissenschaft und Forschung
Al Nuaimi et al. (2015) nennt 3 Vorteile der Big-Data-Analytik, die in Smart Cities angewendet werden können:
- Effiziente Nutzung von Ressourcen
- Bessere Lebensqualität
- Ein höheres Maß an Transparenz und Offenheit
Diese Vorteile erfordern ein hohes Maß an Komplexität und Engagement in Bezug auf Anwendungen, Ressourcen und beteiligte Personen. Die Möglichkeiten, diese Vorteile zu erreichen, sind vorhanden, erfordern jedoch Investitionen in mehr Technologie, bessere Entwicklungsanstrengungen und eine effektive Nutzung von Big Data. Es müssen auch Richtlinien festgelegt werden, um die Genauigkeit, die hohe Qualität, die hohe Sicherheit, den Datenschutz und die Kontrolle der Daten zu gewährleisten. Außerdem müssen Standards für die Datendokumentation verwendet werden, um den Inhalt und die Verwendung von Datensätzen zu erklären (Bertot & Choi, 2013).
Big-Data-Anwendungen haben das Potenzial, viele Bereiche einer intelligenten Stadt zu bedienen. Verbesserung des Gesundheitswesens durch Verbesserung von Präventionsdiensten, Diagnose- und Behandlungsinstrumenten, Verwaltung von Gesundheitsakten und Patientenversorgung. Verkehrssysteme können in hohem Maße von Big Data profitieren, indem sie Routen und Fahrpläne optimieren, unterschiedlichen Anforderungen gerecht werden und umweltfreundlicher sind (Al Nuaimi et al., 2015).
Einige Forschungsarbeiten befassen sich mit der Erhebung von Big Data über Mobiltelefone im Hinblick auf das Reiseverhalten. Choujaa & Dulay (2009) gaben einen Überblick über die Erkennung menschlicher Aktivitäten auf der Grundlage von Handydaten. Deutsch et al. (2012) untersuchten die Erfassung verschiedener Arten von Daten durch verschiedene in Smartphones eingebaute Sensoren und analysierten die Sensorhäufigkeit, Aktivitätsrückschlüsse und den Batterieverbrauch. Calabrese et al. (2014) fassten die Nutzung netzwerkbasierter mobiler Daten für die Stadterkundung zusammen. Steenbruggen et al. (2015) fassten bestehende räumliche Studien auf der Grundlage mobiler Daten zusammen und untersuchten die Möglichkeit, Smart-City-Ziele mit mobilen Daten zu erreichen. Yue et al. (2014) untersuchten, wie verschiedene Arten von Trajektoriendaten, einschließlich Mobilfunkdaten, für Studien zum Reiseverhalten genutzt werden. Liu et al. (2016) befassten sich mit der Problematik der Sammlung, Verarbeitung und Analyse von Big Data in der räumlichen Informationswissenschaft und verwandten Bereichen. Wang et al. (2018) fassten bestehende Studien zum Reiseverhalten unter Verwendung von Mobiltelefondaten zusammen.
Lian et al. (2020) listeten Modelle und Anwendungen von Big Data in der ITS- und CAV-Sicherheitsforschung auf. Sie untersuchten einige Artikel, die Big Data zur Untersuchung der Verkehrssicherheit nutzen. Die meisten der untersuchten Studien konzentrierten sich auf die Erkennung oder Vorhersage von Unfällen, das zweite wichtige Forschungsthema war die Entdeckung von Faktoren, die zu Unfällen beitragen, die Ermittlung von Unfallschwerpunkten und die Analyse des Fahrverhaltens.
Birkin & Malleson (2011) extrahierten vier Monate lang Twitter-Daten von 9223 Nutzern und kombinierten sie anschließend mit GIS-Technologie durch intelligente Modellierung, um die grundlegenden Verhaltensweisen des städtischen Lebens, der Ausbildung, der Arbeit, der Unterhaltung, des Einkaufens und der Reisemuster zu ermitteln. In Kombination mit räumlichen GIS-Daten (Fahrzeuge, Fahrerdaten und Bevölkerung, Flächennutzung, Fernerkundung, Straßennetz, Straßenplanung und das Netz der Verkehrseinrichtungen) wurde eine Vorhersagegrundlage geschaffen. Es gibt jedoch erhebliche ethische Probleme im Zusammenhang mit der Verwendung dieser Daten in solchen Methoden, da sich die Nutzer:innen von Social-Media-Plattformen der Auswirkungen nicht vollständig bewusst sind. Die Nutzer:innen geben nicht wie üblich ihre Zustimmung zur Forschung, und die erhobenen Daten sind nicht streng durch Datenschutzgesetze geschützt. Zumindest sollten Benutzernamen immer verborgen bleiben und Karten mit einer Auflösung verwendet werden, die es unmöglich macht, einzelne Häuser zu identifizieren.
Aktueller Stand der praktischen Umsetzung
In vielen Fällen sind die Einsatzmöglichkeiten von Big Data wahrscheinlich nicht zugänglich. Es wurden jedoch einige Beispiele gefunden.
Im Jahr 2005 nutzte Peking Taxidaten, um den Betrieb des gesamten Straßennetzes der Stadt abzubilden. Bis 2014 war die Zahl der Taxis auf 30 000 gestiegen. Mit der Verbreitung von elektronischen Nummernschildern wird Big Data die Erfassung, Verarbeitung und Analyse des gesamten Fahrverhaltens ermöglichen. Das Pekinger Verkehrsinformationszentrum nutzt nun auch GPS-Daten von Mobiltelefonen, die von China Mobile bereitgestellt werden, um Verkehrsinformationen zu sammeln und die Merkmale der Reiseverteilung der Einwohner:innen zu analysieren (Lian et al., 2020).
Einige Unternehmen haben sich auf Verkehrsdaten spezialisiert. Google bietet einige Daten zur Nutzung an. Zum Beispiel die Anwendungsprogrammierschnittstelle (API) von Google Maps, die mit mehr als 1 Milliarde Erweiterungen weltweit die bei weitem am meisten genutzte Mapping-API ist. Google Maps hat sich zu einer ganzen Reihe von verschiedenen APIs entwickelt. Insgesamt gibt es 14 verschiedene APIs (Damgaard, 2017). Diese sind zum Beispiel:
- Google Maps Places API ermöglicht den Zugriff auf Googles globale Datenbank mit über 100 Millionen Unternehmen und Points of Interest).
- Google Maps Geocoding API kann automatisch eine Adresse anhand einer Stecknadel ermitteln und umgekehrt Adressen in geografische Koordinaten umwandeln
- Google Maps Geolocation API liefert einen Standort und einen Genauigkeitsradius auf der Grundlage von Informationen über Mobilfunkmasten und WiFi-Knoten
- Google Directions API liefert Wegbeschreibungen für eine Reihe von Orten mit verschiedenen Mobilitätsoptionen (Auto, Zug, Fahrrad, zu Fuß)
- Google Map Distance Matrix API liefert Informationen über Entfernung und Reisezeit für verschiedene Ziele unter Berücksichtigung der aktuellen Verkehrssituation
Lau (2020), der Produktmanager von Google Maps, gab an, dass täglich über 1 Milliarde Kilometer mit Google Maps in mehr als 220 Ländern und Gebieten auf der ganzen Welt zurückgelegt werden. Bei der Navigation mit Google Maps können die aggregierten Standortdaten genutzt werden, um die Verkehrsbedingungen auf den Straßen der Welt zu verstehen. Diese Informationen helfen zwar bei der Einschätzung des aktuellen Verkehrsaufkommens, berücksichtigen aber nicht, wie der Verkehr in 10, 20 oder sogar 50 Minuten aussehen wird. Um vorherzusagen, wie der Verkehr in naher Zukunft aussehen wird, analysiert Google Maps historische Verkehrsmuster für Straßen im Laufe der Zeit. Die Datenbank mit den historischen Verkehrsmustern wird mit den aktuellen Verkehrsbedingungen kombiniert, und maschinelles Lernen wird eingesetzt, um auf der Grundlage beider Datensätze Vorhersagen zu treffen.
KI wird eingesetzt, um die Genauigkeit der Verkehrsprognosen weiter zu verbessern. Die Vorhersagen haben bereits eine Genauigkeit von über 97 %, aber es wird erwartet, dass der Prozentsatz der ungenauen Ankunftszeiten durch eine Architektur des maschinellen Lernens, die als Graph Neural Networks bekannt ist, noch weiter sinken wird - mit deutlichen Verbesserungen an Orten wie Berlin, Jakarta, São Paulo, Sydney, Washington D.C. und Tokio. Diese Technik ermöglicht es Google Maps, besser vorherzusagen, ob Autofahrer:innen von einem Stau betroffen sein werden, der vielleicht noch gar nicht begonnen hat. Die durch den Ausbruch der Pandemie COVID 19 verursachten Mobilitätsveränderungen haben zu einem Rückgang des weltweiten Verkehrsaufkommens um bis zu 50 % geführt. Danach haben sich Teile der Welt allmählich wieder geöffnet, während in anderen Teilen weiterhin Beschränkungen gelten. Um auf diese plötzlichen Veränderungen zu reagieren, hat Google seine Modelle aktualisiert, um flexibler zu werden (historische Verkehrsmuster aus den letzten zwei bis vier Wochen werden priorisiert und Muster aus der Zeit davor werden depriorisiert). Die Vorhersage des Verkehrsaufkommens und die Festlegung von Routen ist jedoch unglaublich komplex, und es wird weiter an Werkzeugen und Technologien gearbeitet, um Staus zu vermeiden.
Jedoch ist es wichtig, einen Blick auf den Energieverbrauch im Zusammenhang mit Big Data zu werfen: Schätzungen zufolge werden jährlich etwa 200 Terawattstunden (TWh) verbraucht. Dies entspricht der Hälfte des weltweiten Stromverbrauchs für den Verkehr und etwa 1 Prozent des globalen Strombedarfs und stellt eine enorme ökologische Herausforderung dar. Während Computer auf Systemebene eine Nettoreduzierung des Energieverbrauchs ermöglichen (durch geringeren Transportaufwand, bessere Fertigungstechniken usw.), führt die zunehmende Computernutzung zu einer Zunahme der Rechenzentren und einem Trend zu Geräten mit höherer Dichte und höherer Verarbeitungsleistung, was zu einem Anstieg des Energieverbrauchs und der Emissionen auf lokaler Ebene führt. Infolgedessen ist die Informations- und Kommunikationstechnologie (IKT) einer der größten Sektoren, die Energie verbrauchen (Lovell, 2018).
Relevante Initiativen in Österreich
Auswirkungen in Bezug auf die Ziele für nachhaltige Entwicklung (SDGs)
| Ebene der Auswirkungen | Indikator | Richtung der Auswirkungen | Beschreibung des Ziels & SDG | Quelle |
|---|---|---|---|---|
| Individuell | Erhoehung der Fahrzeugsicherheit | + | Gesundheit und Wohlbefinden (3) | Lian et al., 2020 |
| Individuell | Effizienterer Kraftstoffverbrauch | + | Oekologische Nachhaltigkeit (7,12-13,15) | Al Nuaimi et al., 2015 |
| Systemisch | Verkuerzte Reisezeit | + | Gesundheit und Wohlbefinden (3) | Lau, 2020 |
| Systemisch | Erhoehter Energieverbrauch | - | Oekologische Nachhaltigkeit (7,12-13,15) | Lovell, 2018 |
Technologie- und gesellschaftlicher Bereitschaftsgrad
| Stand der Technologiebereitschaft | Gesellschaftlicher Bereitschaftsgrad |
|---|---|
| 5-7 | 5-7 |
Offene Fragen
- Wie viele Daten braucht man, um als Big Data-Analytik zu gelten?
Referenzen
- Al Nuaimi, E., Al Neyadi, H., Mohamed, N., & Al-Jaroodi, J. (2015). Applications of big data to smart cities. Journal of Internet Services and Applications, 6(1), 25. https://doi.org/10.1186/s13174-015-0041-5
- Anagnostopoulos, I., Zeadally, S., & Exposito, E. (2016). Handling big data: research challenges and future directions. Journal of Supercomputing, 72(4), 1494–1516. https://doi.org/10.1007/s11227-016-1677-z
- Bertot, J. C., & Choi, H. (2013). Big Data and E-Government: Issues, Policies, and Recommendations. Proceedings of the 14th Annual International Conference on Digital Government Research, 1–10. https://doi.org/10.1145/2479724.2479730
- Birkin, M., & Malleson, N. (2011). Microscopic Simulations of Complex Flows (Issue December). http://eprints.ncrm.ac.uk/2051/1/complex_city_paper[1].pdf
- Calabrese, F., Ferrari, L., & Blondel, V. D. (2014). Urban Sensing Using Mobile Phone Network Data: A Survey of Research. ACM Comput. Surv., 47(2). https://doi.org/10.1145/2655691
- Choujaa, D., & Dulay, N. (2009). Activity recognition from mobile phone data: State of the art, prospects and open problems. Imperial College London, 1–32.
- Damgaard, M. (2017, September 7). Google Maps APIs - How to choose the right API key type? | MapsPeople. https://www.mapspeople.com/blog/mapsindoors/google-maps-api-description/?utm_term=google maps api&utm_campaign=Google+Maps+API+(Fokusmarkeder)&utm_source=adwords&utm_medium=ppc&hsa_acc=1756747029&hsa_cam=9568964808&hsa_grp=100103134522&hsa_ad=477511645844&hsa_src=g&hsa_tgt=aud-1074199825348:kwd-336979256761&hsa_kw=google maps api&hsa_mt=p&hsa_net=adwords&hsa_ver=3&gclid=CjwKCAjwx8iIBhBwEiwA2quaq37WdAzuUTzEEynIONxqGOL7V_62jAgOvV_H2B6kB9kJtjva-90xABoCtacQAvD_BwE
- Deutsch, K., Mckenzie, G., Janowicz, K., Li, W., Hu, Y., & Goulias, K. (2012). Examining the use of smartphones for travel behavior data collection. International Conference on Travel Behaviour Research, July, 1–10.
- Fan, W., & Bifet, A. (2013). Mining Big Data: Current Status, and Forecast to the Future. SIGKDD Explor. Newsl., 14(2), 1–5. https://doi.org/10.1145/2481244.2481246
- Kramers, A., Höjer, M., Lövehagen, N., & Wangel, J. (2014). Smart sustainable cities - Exploring ICT solutions for reduced energy use in cities. Environmental Modelling and Software, 56, 52–62. https://doi.org/10.1016/j.envsoft.2013.12.019
- Lau, J. (2020, September 3). Google Maps 101: How AI helps predict traffic and determine routes. https://blog.google/products/maps/google-maps-101-how-ai-helps-predict-traffic-and-determine-routes/
- Lian, Y., Zhang, G., Lee, J., & Huang, H. (2020). Review on big data applications in safety research of intelligent transportation systems and connected/automated vehicles. Accident Analysis and Prevention, 146(September), 105711. https://doi.org/10.1016/j.aap.2020.105711
- Liu, J., Li, J., Li, W., & Wu, J. (2016). Rethinking big data: A review on the data quality and usage issues. In ISPRS Journal of Photogrammetry and Remote Sensing (Vol. 115, pp. 134–142). Elsevier B.V. https://doi.org/10.1016/j.isprsjprs.2015.11.006
- Lovell, A. (2018). Big data: A big energy challenge? Available at: https://www.energycouncil.com.au/analysis/big-data-a-big-energy-challenge/ [Accessed: 11 August 2021]
- Machay, J. (n.d.). How Does Google Detect Traffic Congestion? Available at: https://smallbusiness.chron.com/google-detect-traffic-congestion-49523.html [Accessed: 10 August 2021]
- Manyika, J., Institute, M. G., Chui, M., Brown, B., Bughin, J., Dobbs, R., Roxburgh, C., & Hung Byers, A. (2011). Big Data: The next frontier for innovation, competition, and Productivity. McKinsey Global Institute. Available at: http://hdl.handle.net/2324/3144682 [Accessed: 4 August 2021]
- McAfee, A., Brynjolfsson, E., Davenport, T. H., Patil, D. J., & Barton, D. (2012). Huge data: The the executives transformation. Harvard Bus Rev, 90(10), 60 68.
- NCTA. (2013, July 3). How Google Tracks Traffic | NCTA — The Internet & Television Association. Available at: https://www.ncta.com/whats-new/how-google-tracks-traffic [Accessed: 4 May 2021]
- Qin, X., Zhen, F., Xiong, L. F., & Zhu, S. J. (2013). Methods in urban temporal and spatial behavior research in the big data era. Progress in Geography, 32(9), 1352–1361.
- Sagiroglu, S., & Sinanc, D. (2013). Big data: A review. 2013 International Conference on Collaboration Technologies and Systems (CTS), 42–47. https://doi.org/10.1109/CTS.2013.6567202
- Steenbruggen, J., Tranos, E., & Nijkamp, P. (2015). Data from mobile phone operators: A tool for smarter cities? Telecommunications Policy, 39(3–4), 335–346. https://doi.org/10.1016/j.telpol.2014.04.001
- Wang, P., Huang, Z.-R., & Gong, H. (2013). Transportation engineering in the big data era. Dianzi Keji Daxue Xuebao/Journal of the University of Electronic Science and Technology of China, 42(6), 806–816. https://doi.org/10.3969/j.issn.1001-0548.2013.06.002
- Wang, Z., He, S. Y., & Leung, Y. (2018). Applying mobile phone data to travel behaviour research: A literature review. Travel Behaviour and Society, 11, 141–155. https://doi.org/10.1016/j.tbs.2017.02.005
- Yue, Y., Lan, T., Yeh, A. G. O., & Li, Q. Q. (2014). Zooming into individuals to understand the collective: A review of trajectory-based travel behaviour studies. Travel Behaviour and Society, 1(2), 69–78. https://doi.org/10.1016/j.tbs.2013.12.002
- Zhao, Y., Zhang, H., An, L., & Liu, Q. (2018). Improving the approaches of traffic demand forecasting in the big data era. Cities, 82, 19–26. https://doi.org/10.1016/j.cities.2018.04.015